

1. 准确率
2. 速度
3. 强壮性
4. 可规模性
5. 可解释性
决策树是机器学习中分类方法中一个重要的算法
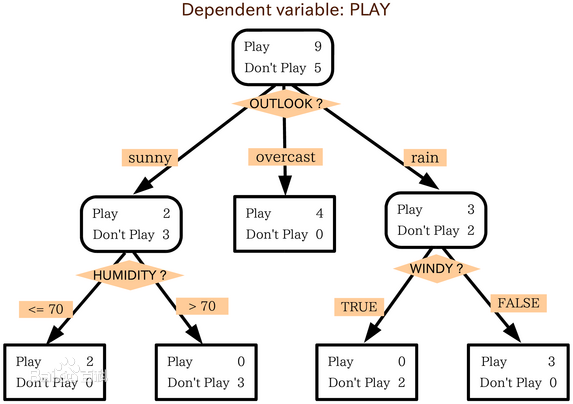
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点
优点:直观,便于理解,小规模数据集有效
缺点:处理连续变量不好 ,类别较多时,错误增加的比较快 ,可规模性一般
一条信息的信息量大小和它的不确定性有直接的关系
信息量的度量就等于不确定性的多少
变量的不确定性越大,熵越大
优先选择信息获取量最大的属性作为属性判断结点
信息获取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)
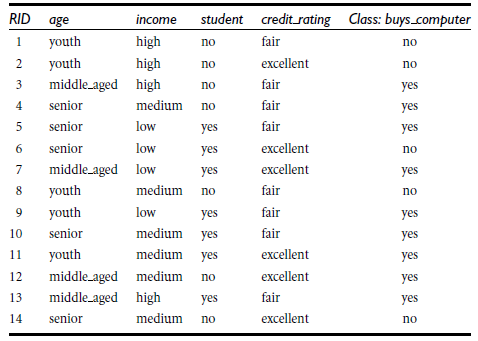
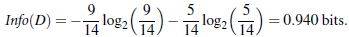
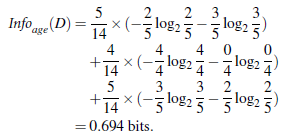
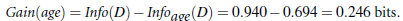
同理,计算income,student,credit_rating的信息获取量,因为age的信息获取量最大,所以首先将age属性作为节点来分枝
C4.5: Quinlan
Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)
共同点 都是贪心算法,自上而下(Top-down approach)
区别 属性选择度量方法不同: C4.5 (gain ratio), CART(gini index), ID3 (Information Gain)
离散化(阈值的选择很关键)
先剪枝 后剪枝
;C:\Program Files (x86)\Graphviz2.38\bin1. 将原始数据录入[csv文件](/blog/static/img/ml/01-06.csv)
2. 引入sk-learn相关的package
3. 读取csv文件的数据到程序中
4. 对数据预处理
5. 决策树分类的核心代码
6. 生成dot文件(结果不够直观)
dot文件:
7. 将dot文件用graphviz转换为pdf文件
在命令行下,cd到你的dot文件的路径下,输入
`dot -Tpdf filename.dot -o output.pdf`
#coding=gbk
# DictVectorizer:数据类型转换
from sklearn.feature_extraction import DictVectorizer
# csv:原始数据放在csv文件中,该package为python自带,不需要安装
import csv
#引入sk-learn数据预处理包、决策树包、读写字符串包
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
#从csv文件中读取数据,并保存到allElectronicsData变量中
allElectronicsData = open(r'.\01-06.csv','r')
# csv的reader方法按行读取数据
reader = csv.reader(allElectronicsData)
#next方法读取到csv文件的第一行数据
headers = next(reader)
#打印第一行数据
print(headers)
#建两个list,featureList装特征值,labelList装类别标签
featureList = []
labelList = []
#遍历csv文件的每一行
for row in reader:
#将类别标签加入到labelList中
labelList.append(row[len(row)-1])
#下面这几步的目的是为了让特征值转化成一种字典的形式,就可以调用sk-learn里面的DictVectorizer,直接将特征的类别值转化成0,1值
rowDict = {}
for i in range(1,len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
#实例化
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:"+str(dummyX))
print(vec.get_feature_names())
# label的转化,直接用preprocessing的LabelBinarizer方法
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:"+str(dummyY))
print("labelList:"+str(labelList))
#criterion是选择决策树节点的标准,这里是按照“熵”为标准,即ID3算法;默认标准是gini index,即CART算法。
clf = tree.DecisionTreeClassifier(criterion = 'entropy')
clf = clf.fit(dummyX,dummyY)
print("clf:"+str(clf))
#生成dot文件
with open("allElectronicInformationGainOri.dot",'w') as f:
f = tree.export_graphviz(clf,feature_names = vec.get_feature_names(),out_file = f)
#测试代码,取第1个实例数据,将001->100,即age:youth->middle_aged
oneRowX = dummyX[0,:]
print("oneRowX:"+str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX:"+str(newRowX))
#预测代码
predictedY = clf.predict(newRowX)
print("predictedY:"+str(predictedY))
执行:python 01-07.py
参考文档 sk-learn的决策树文档