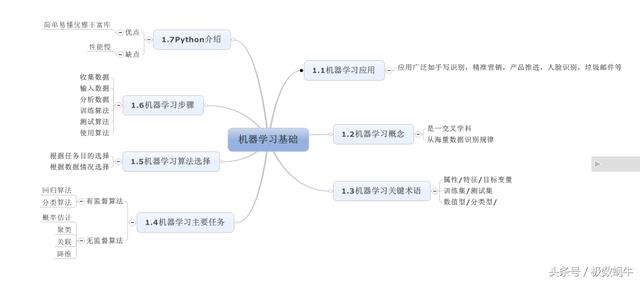
机器学习是什么
卡内基梅隆大学Tom Mitchell :一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值P(成功率),当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升
机器学习是横跨计算机科学、工程科学和统计学等多学科的交叉科学,能够从海量的数据中发现数据规律和有用信息。该学科是人工智能的一个发展方向。
机器学习分类
- 监督学习:我们将教计算机如何去完成任务,给学习算法一个数据集,每个样本都有“正确答案”,再根据样本作出预测组成 回归问题:推测出一个连续值的结果 分类问题:推出一组离散的结果 例子:回归、决策树、随机森林、K – 近邻算法、逻辑回归等
- 无监督学习:让计算机自己进行学习完成任务,在算法中,没有任何目标变量或结果变量要预测或估计,已知数据集,却不知如何处理,从数据中找到某种结构 组内聚类分析、细分客户 例子:关联算法和 K – 均值算法
- 强化学习(训练机器进行决策):机器被放在一个能让它通过反复试错来训练自己的环境中。机器从过去的经验中进行学习,并且尝试利用了解最透彻的知识作出精确的商业判断
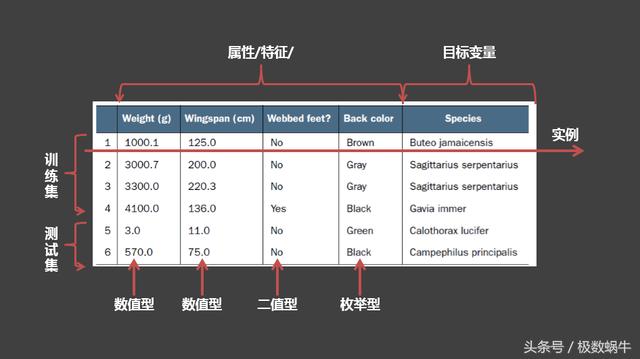
关键术语
主要任务
分类和回归:分类主要是将数据集划分到合适的类别中,而回归是预测数值型数据,通过曲线拟合来预测数据。该两类算法都被称为监督算法,因为他们知道预测什么,即有目标变量。与之对应的是无监督算法,包括聚类、密度估计和降维等 
选择合适机器学习算法
在选择合适算法之前,需要考虑两个问题: 一是算法任务目的是什么,是预测概率还是分类; 二是收集的数据是什么,是图片、文本、视频等类型,是否有缺失值和异常值等 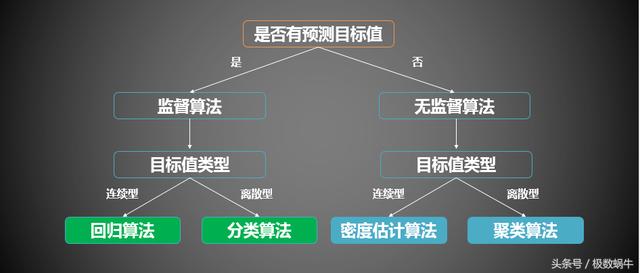
机器学习是步骤
(1) 学习算法的原型搭建(工具:Octave)
- 收集数据:收集样本数据。如网络爬虫、API、物联网设备、网络数据等。在学习的时候可以使用公开的数据集。可参考文章中介绍的数据集。
- 输入数据:将收集的数据进行清洗,保证数据格式符合算法或编程操作的样式。如Python的list格式的。数据类型的格式化,字符型还是数字型。
- 分析数据:分析数据是否有脏数据,如异常值,缺失值等情况,另外通过分析选择相关的特征属性,减少计算量。
- 训练算法:选择合适算法对模型进行训练,该步骤是关键核心。
- 测试算法:主要是对第4步训练的模型,用测试集评估该算法的性能,如准确率。
- 使用算法:将获得的算法开发成程序,来执行实际任务,并来反馈是否能够真正在现实生活中得到应用,并根据实际应用效果来优化算法。
(2) 工作后
(3) 移植它到 C++或 Java 或别的语言
Python简单介绍
Python是一门高级面向对象语言,主要优点有:
(1)语法清晰,结构简单,优雅。对于没有编程经验的初学者,也是很容易上手。被称为“可执行伪代码”。
(2)在各领域应用广泛,代码范例比较多,便于快速学习。另外,还有很丰富的数据库和模块,如SciPy和NumPy等。
(3)便于操作各种文本文件,如Excel,txt,CSV,图片等。
但唯一缺点是性能问题,运算效率不如Java和C代码高。但是可以通过Python调用C编译的代码,可以在一定程度上解决性能问题。
机器学习算法中的运算很多是根据矩阵来运算的,而Python中的NumPy函数库就聚合了该功能。比如矩阵相乘,求矩阵逆,单位矩阵等都很easy。
机器学习基础的思维导图